



Artificial Intelligence (AI) will and is currently taking over an important role in our lives – not necessarily through intelligent robots – but a learning algorithm is implemented in many intelligent technologies. Also, Machine Learning and Deep Learning are contemporary important terms in Computer Science. But those AI-related terms are often mixed up or falsely taken as synonyms, which will be clarified in the following.
The word “intelligence” alone is quite hard to define. One can try it through probably the most popular method: The Turing Test. It argues that intelligence can be identified behavior-based. For instance, regarding a chat-bot, one could say: If it is undistinguishable if the chat partner is a human or computer, the computer can be entitled as “intelligent”, even if it is just an imitation game without any awareness on the computer’s side. Consequently, intelligence has not necessarily something to do with human intelligence. The term Artificial Intelligence was primarily introduced by John McCarthy in 1956 offering a seminar with this as a title. He is therefore often referred to as the Father of AI. He stated: “The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it” and therefore sets a first stone in characterizing Artificial Intelligence. Initially, Machine Learning was not separated from the field of AI, which changed in the 1990s: The scientists started to tackle practical problems and went away from symbolic approaches regarding intelligence. The term of Deep Learning appeared in the year 2000 for the first time describing an Artificial Neural Network.
What is Artificial Intelligence?
Everyone might have some applications in mind coming from utopias presented in film and fiction or media. AI is basically working with a goal, which is trying to enable machines to make decisions. As already mentioned, the word intelligence can be misleading. Therefore, we now want to go back to the basics trying to bring the fundamental idea of these technologies to you by using examples. One popular example is using oranges and apples. The goal is to teach the machine what an apple and an orange look like and enabling it to separate them. Each fruit has certain features, which have to be told to the algorithm: An apple is red or green, whereas an orange is orange. It has a bumpy surface, while the apple is smooth. Translated to English, you implement in the algorithm: “If something is red or green, is round and has a smooth texture, you call it an apple” and “If something is orange, round and has a bumpy texture you call it an orange”. And this is the first step one must take when it comes to programming an AI-powered software. If the software now recognizes the mentioned features, it can give the output “orange” or “apple”. As a code it looks like this:
In this code certain features of oranges and apples are defined
We can set: Artificial Intelligence means enabling a machine to think and mimic human behavior as it is now possible to take its own decisions.
What is Machine Learning?
The algorithm can now decide, whether it is seeing an orange or an apple, because we taught the software what the features of each fruit are and therefore enabled it to decide on its own. This is all fun and games until you cut the orange into eatable pieces. A human can still recognize the apple as apple, but how should the software be able to do it when it goes by an apple being round? It cannot. Now you give the software many pictures of apples in different angles, cut in pieces or in different color shades and add information: Those are all apples. Of course, it is the same with categorizing oranges. The software can now recognize apples and oranges in almost every shape – depending on the amount of data given. How much data is needed as minimum is depending on the application, but there are some good clues. At a bare minimum there should be around 1,000 examples. For average problems with mid complexity 10,000 to 100,000 examples are needed. Regarding the amount of data one can conject: The more the better. Machine Learning is therefore not only about decisions, but rather about being able to broaden your horizon.
We can set: Machine Learning is a statistical tool that enables the machine to learn from given data or experience.
What is Deep Learning?
As all important inventions of humankind, the field of AI also uses nature as a role model. Deep Learning (DL) is working through a Deep Neural Network orienting itself on the human brain. The Artificial Networks are built with different layers consisting of connected neurons. Each layer can have a special purpose, for example learning to detect patterns in the data, which enables it to recognize objects as the same ones. Another function can be looking for specific pre-set patterns, like a round, red or green object with a smooth surface and considering it as an apple. The information that this is called an apple must be given by human help. Whereas finding out that it is still an apple, even if one half is in the shadow, is something that can be learned unsupervised (without human help) by the algorithm through training data. One should mention that an Artificial Network is not nearly as complicated as a natural one and is not on a human-level intelligent or thinking human-like. Regarding the information processing there are no electrical or chemical impulses rather than a signal being zero or one. But it is indeed inspired by nature and transferred to technology: While a single neuron is not capable of doing something, a whole Neural Network is extremely complex. The behavior of the system is determined by the ways how the neurons are wired together. Each neuron reacts to the incoming signals in a specific way that can also adapt over time. DL is for example also applied in Language Processing. The Artificial Network analyses parts of the speech, like sentence structure, specific word-use or phrases. This allows the algorithm to do natural Language Processing (NLP) and puts the human-machine interaction on a whole new level. This means having a chat with a computer feels like talking to a human.
We can set: Deep Learning is enabling the machine to mimic the human brain through artificial neurons and therefore can identify important features on its own.
It is all connected
There is basically no common definition of Artificial Intelligence and sometimes it is hard to decide whether something can be called Artificial Intelligence or not. Each of the mentioned technologies are connected and part of each other: Deep Learning is a part of Machine Learning, which itself is a part of Artificial Intelligence.
Deep Learning is considered to be a part of Machine Learning, while it is a part of Artificial Learning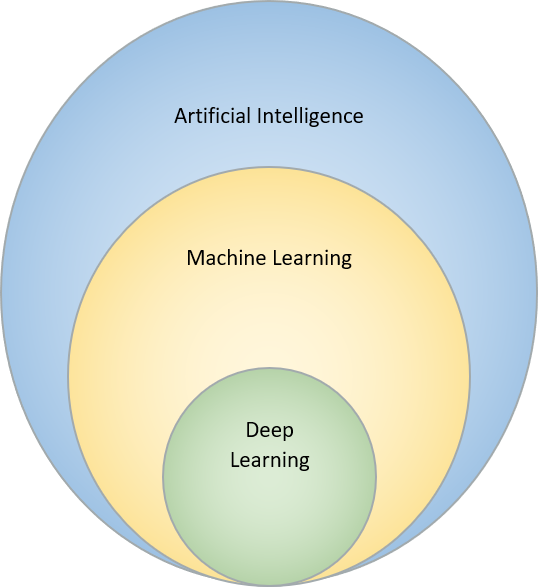
Taking one step back, the word “intelligence” alone is quite hard to define. As explained previously, the Turing Test is a common method. It argues, that something can be identified as intelligent only due to its behavior. Regarding a chat-bot one could say that if it is indistinguishable if it is a human or computer on the other side, the behavior could be determined as “intelligent”, even if it is just an imitation game without any awareness on the computer’s side. And we remember: Even an Artificial Neural Network is only orienting on its natural role model, but is not truly comparable to one. Every intelligent outcome a computer provides is based on the training data given. As mentioned previously regarding the training data one can assess: The more relevant data, the better. This is where the field of AI is related to Data Science. Even the best software-code in the world is worth nothing without sufficient data to learn from it.
Artificial Intelligence is a part of Data Science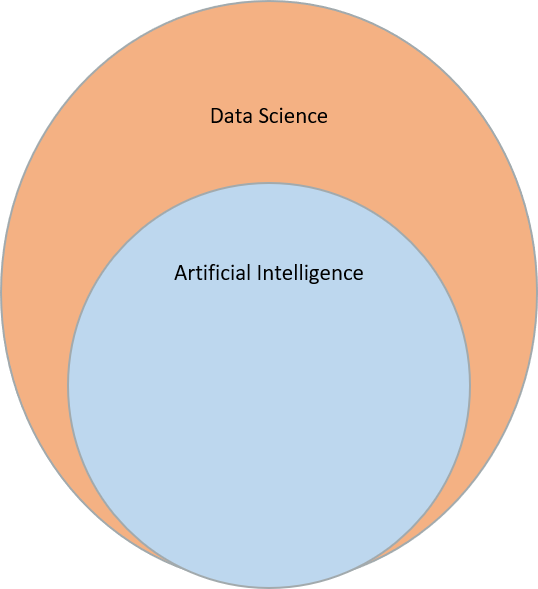
Methods and problems
For Deep Learning we are data-wise not talking about a bare minimum of around 1,000 examples, but rather around 100,000 to 1,000,000 examples to learn from. We are now getting into Big Data spheres in the field of Data Science. This term is also connected to the field of Artificial Intelligence in the way of AI being a part of Data Science. Since one cannot always offer this amount of data, the principle of heuristics can be pulled up. This method uses the information it has and estimates an outcome for the next step based on that. Taking chess-playing as a popular example, the program has the value and position of all figures as input and therefore can predict possible outcomes like losing a figure or winning the game. Despite this is often enough to solve a problem, it is no precise solution. The human brain uses the concept of heuristics daily, hence this is another aspect, where nature as role model can be noticed.
Besides self-driving cars and image processing of oranges and apples as an example, the state-of-the-art applications are already integrated in our daily lives. For instance, in streaming services each personal recommendation is based on AI-driven algorithms using your data. Here, another example that can be added to the picture processing of our fruit salad: The nearest neighbor classification. Here, the habits of each user are tracked: What kind of movies or series did he or her watch and how did he or her rate them? And now the algorithm compares all users to each other, assuming that people having similar consuming habits might like the same kind of content. For both applications one thing is sure: There is a huge amount of data needed – the more, the better. Hence, the less training data is available the worse is the software’s performance, which is is considered as huge problem for many applications.
Hunger for more knowledge
If you want to learn more about Artificial Intelligence and do some research on Artificial Intelligence, we can recommend a free and open AI online course developed by the University of Helsinki. It is the AI researchers’ aim to educate at least 1% of the world’s society about Artificial Intelligence.



