
/ 6 Minuten Lesezeit
Was ist Künstliche Intelligenz, Maschinelles Lernen und Deep Learning?
Künstliche Intelligenz (KI) nimmt derzeit und wird auch in Zukunft eine immer wichtigere Rolle in unserem Leben einnehmen – nicht unbedingt nur durch intelligente Roboter, denn ein lernender Algorithmus ist in vielen intelligenten Technologien implementiert. Außerdem sind Maschinelles Lernen und Deep Learning derzeit wichtige Themen in der Computerwissenschaft. Aber die KI-bezogenen Themenfelder werden häufig verwechselt oder fälschicherweise als Synonyme verwendet, was im Folgenden klargestellt werden soll.
Das Wort “Intelligenz” ist schwer zu definieren. Die wahrscheinlich beliebteste Methode es zu versuchen ist der Turing-Test. Dieser argumentiert, dass Intelligenz verhaltensbasiert definiert werden kann. Für das Beispiel eines Chat-Bots würde demnach gelten: Ist nicht zu unterscheiden, ob der Chat-Partner ein Mensch oder ein Computer ist, kann dieser als „intelligent“ bezeichnet werden, auch wenn der Computer nur imitiert und kein Bewusstsein hat. Demnach hat Intelligenz nicht zwingend etwas mit menschlicher Intelligenz zu tun. Der Begriff Künstliche Intelligenz wurde erstmals von John McCarthy im Jahr 1956 verwendet, als er ein Seminar mit dem Begriff im Titel veröffentlichte. Er wird aus diesem Grund häufig als Vater von KI angesehen. Der Forscher definierte: “Jeder Aspekt des Lernens und andere Eigenschaften von Intelligenz können im Prinzip so präzise beschrieben werden, dass eine Maschine sie simulieren kann.“ Damit machte er den ersten Definitionsversuch von Künstlicher Intelligenz. Initial war Maschinelles Lernen nicht vom Feld der KI getrennt, was sich in den 1990ern änderte: Die Wissenschaftler begannen praktische Probleme zu behandeln und entfernten sich damit von theoretischen Annäherungen an Intelligenz. Der Ausdruck Deep Learning kam das erste Mal im Jahr 2000 auf, um ein künstliches neuronales Netzwerk zu beschreiben.
Was ist künstliche Intelligenz?
Viele haben wahrscheinlich einige Anwendungen im Kopf, die aus Filmutopien, Fiktion oder Medien stammen. KI arbeitet grundsätzlich auf das Ziel hin, es Maschinen zu ermöglichen Entscheidungen zu treffen. Das Wort Intelligenz kann in diesem Zusammenhang irreführend sein. Deshalb noch einmal zurück zu den Basics, um die grundlegende Idee dieser Technologie anhand von Beispielen zu verstehen. Häufig werden dazu Orangen und Äpfel verwendet. Das Ziel ist es, einer Maschine beizubringen wie ein Apfel und eine Orange aussehen und sie diese auseinander halten zu können. Jede Frucht hat bestimmte Merkmale, die dem Algorithmus beigebracht werden müssen: Ein Apfel ist rot oder grün, während eine Orange orangefarben ist. Sie hat eine unebene Oberfläche, während ein Apfel glatt ist. Übersetzt bedeutet das dem Algorithmus zu sagen: “Wenn etwas rot oder grün ist, rund und mit glatter Oberfläche, nennt man das einen Apfel“ und „Wenn etwas ist orange, rund und eine unebene Oberfläche, nennt man das eine Orange.“ Das ist der erste Schritt, wenn es um die Programmierung einer KI-basierten Software geht. Erkennt die Software nun die genannten Merkmale, gibt sie den Output „Orange“ oder „Apfel“. Als Code sieht das ganze so aus:
In diesem Code werden bestimmte Eigenschaften von Orangen und Äpfel definiert

Wir können festhalten: Künstliche Intelligenz hat zum Ziel eine Maschine gewissermaßen zum Denken zu bringen und menschliches Benehmen nachzuahmen, indem sie eigene Entscheidungen treffen kann.
Was ist Maschinelles Lernen?
Der Algorithmus kann nun entscheiden, ob er eine Orange oder einen Apfel sieht, weil wir der Software beigebracht haben, welche Frucht welche Merkmale hat und ihr dadurch ermöglichten, eine Entscheidung zu treffen. Das funktioniert so auch gut, bis zu dem Punkt, an dem die Orange oder der Apfel in mundgerechte Stücke geschnitten werden. Ein Mensch kann einen Apfel auch dann noch als Apfel identifizieren. Wie aber soll das eine Maschine erkennen, wenn sie davon ausgeht, dass Äpfel immer rund sind? Ganz einfach: kann sie nicht. Das bedeutet, dass man der Softaware nun auch viele Bilder von Äpfeln zeigen muss, die in Stücke geschnitten sind oder zum Beispiel eine andere Form haben. Man sagt ihr: Das sind alles Äpfel. Natürlich muss das gleiche auch noch mit den Orangen passieren. So kann die Software Äpfel und Orangen theoretisch in fast allen Formen erkennen. Das ist allerdings auch noch abhängig von der Menge an Daten, die zur Verfügung stehen. Wie viele Daten dabei mindestens gebraucht werden, hängt vom genauen Anwendungsfall ab, doch es gibt ein paar grobe Werte als Anhaltspunkt. Als niedrigstes Minimum werden immer etwa 1.000 Beispiele angesehen, mit weniger Daten funktioniert der KI-Algorithmus nicht. Für durchschnittliche Probleme muss man etwa 10.000 bis 100.000 Beispiele bereitstellen. Dabei gilt grundsätzlich: Je mehr, desto besser. Beim Maschinellen Lernen geht es also nicht nur um Entscheidungen, ob es zum Beispiel ein bestimmtes Objekt ist, sondern darum, den Horizont des Algorithmus zu erweitern.
Wir können festhalten: Maschinelles Lernen ist ein statistisches Werkzeug, das der Maschine ermöglicht von Daten oder Erfahrungen zu lernen.
Was ist Deep Learning?
Wie alle wichtigen Erfindungen der Menschheit, hat auch der Bereich KI die Natur zum Vorbild. Deep Learning (DL) arbeitet mit einem tiefen neuronalen Netzwerk, das sich am menschlichen Gehirn orientiert. Künstliche Netzwerke werden aus verschiedenen Lagen gebildet, die aus miteinander verbundenen Neuronen bestehen. Jede Lage kann einen speziellen Zweck erfüllen, beispielsweise Muster in den Daten zu erkennen, die es ermöglichen Objekte als solche zu identifizieren. Eine andere Funktion kann es zu sein, vorher definierte Muster zu finden, zum Beispiel ein rundes, rotes Objekt mit glatter Oberfläche und dies im nächsten Schritt als Apfel zu bezeichnen. Die Information, dass die Bezeichnung “Apfel” ist, muss vorher von Menschen definiert werden. Geht es aber darum zu erkennen, dass ein Apfel immer noch ein Apfel ist, auch wenn er geschnitten ist, kann ein Algorithmus unbeaufsichtigt (ohne menschliche Hilfe) allein mit Hilfe von Trainingsdaten lernen. Klar ist, dass ein künstliches Netzwerk nicht annähernd so komplex ist, wie ein natürliches und es nicht auf menschliche Art und Weise intelligent ist oder menschlich denkt. Die Informationsweiterleitung ist zum Beispiel ganz unterschiedlich: Es gibt keine elektrischen oder chemischen Impulse, sondern Signale, die entweder den Wert 1 oder 0 haben. Doch die Inspiration und die Idee kommen aus der Natur und wurden auf die Technologie übertragen und versucht nachzubilden. Eine Gemeinsamkeit ist beispielsweise, dass ein einziges Neuron nutzlos ist, während die Kombination aus vielen Neuronen als neuronales Netzwerk komplexe Aufgaben lösen kann. Das Ergebnis ist vor allem davon bestimmt, wie die Neuronen angeordnet und miteinander verbunden sind.
Eine häufige Anwendung von DL ist zum Beispiel die Sprachverarbeitung. Das künstliche Netzwerk analysiert dabei Teile der Sprache, wie Satzstruktur oder die Verwendung bestimmter Worte und Phrasen. Das erlaubt dem Algorithmus Sprache natürlich zu verwenden. Damit wird die Mensch-Maschine-Interaktion auf ein ganz neues Level gehoben, denn plötzlich fühlt sich ein Chat mit einem Computer an wie zwischenmenschliche Kommunikation.
Wir können festhalten: Deep Learning ermöglicht es einer Maschine das menschliche Gehirn mit künstlichen Neuronen nachzuahmen und dadurch wichtige Merkmale selbstständig zu erkennen.
Es hängt alles zusammen
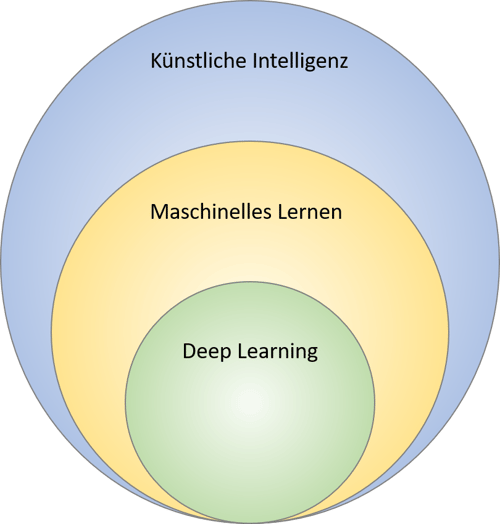
Im Grunde gibt es keine einheitliche Definition von Künstlicher Intelligenz und manchmal ist es schwer zu entscheiden, ob etwas als Künstliche Intelligenz bezeichnet werden kann oder nicht. Jede der erwähnten Technologien ist mit der anderen verbunden und ein Teil der anderen: Deep Learning ist ein Teilgebiet von Maschinellem Lernen, was wiederum selbst ein Teilgebiet der Künstlichen Intelligenz ist.
Deep Learning ist ein Teil des Maschinellen Lernens, während das wiederum ein Teil der Künstlichen Intelligenz ist
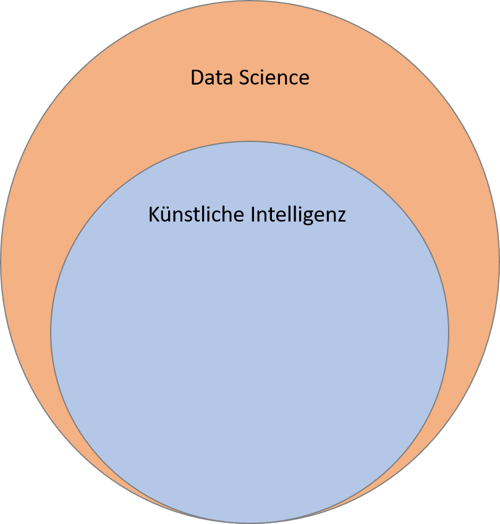
Geht man noch einmal einen Schritt zurück, ist allein schon das Wort „Intelligenz“ schwer zu definieren. Wie vorher erklärt, wird meist der Turing Test dafür herangezogen. Dieser argumentiert, dass etwas aufgrund seines Verhaltens als intelligent bezeichnet werden kann. Für einen Chat-Bot würde demnach gelten: Kann nicht unterschieden werden, ob auf der Kommunikationspartner ein Mensch oder eine Maschine ist, kann das Verhalten als intelligent gelten und zwar auch, wenn eine Maschine kein Bewusstsein hat und im Grunde nur Verhalten imitiert. Wir wissen bereits: Auch ein künstliches neuronales Netzwerk orientiert sich an seinem natürlichen Vorbild, vergleichbar macht sie das jedoch nicht wirklich. Jedes intelligente Ergebnis, das ein Computer generiert, basiert auf Daten. Hier gilt, wie bereits erwähnt: Je mehr, desto besser. Hier geht das Gebiet von KI in die Datenwissenschaft über, denn sogar der beste Software-Code der Welt ist nichts Wert ohne Daten, von denen er lernen kann.
Künstliche Intelligenz ist ein Teil der Data Science
Methoden und Probleme
Bei Deep Learning geht es was die Daten angeht nicht von mindestens 1.000 Beispielen, sondern vielmehr um 100.000 bis 1.000.000. Man spricht dann von Big Data aus dem Bereich der Datenwissenschaft. Da man nicht einfach so solch große Datenmengen zur Hand hat, wird oft das Prinzip der Heuristik angewendet. Diese Methode verwendet die vorhandenen Informationen und schätzt anhand von Wahrscheinlichkeiten ein Ergebnis für den nächsten Schritt ab. Nimmt man Schachspielen als bekanntes Beispiel, hat das Programm Werte und Positionen aller Figuren als Daten und kann darauf basierend damit mögliche Ergebnisse vorhersagen. Das könnte zum Beispiel sein eine Figur zu verlieren oder auch das Spiel zu gewinnen. Oftmals reicht das aus, um ein Problem zu lösen, obwohl kein präzises Ergebnis vorliegt. Das menschliche Gehirn nutzt das Prinzip der Heuristik täglich und schätzt Konsequenzen für Entscheidungen ab. Es ist also ein weiterer Aspekt, bei dem die Natur als Vorbild dient.
Neben der Bildverarbeitung von Orangen und Äpfeln, sind state-of-the-art Anwendungen bereits in unseren Alltag integriert. Zum Beispiel basiert jede persönliche Empfehlung in Streamingdiensten auf KI-Algorithmen, die mit unseren Daten arbeiten. Hier wird eine andere Methodik angewendet, die nächster-Nachbar-Klassifikation. Dabei werden die Gewohnheiten von Nutzer:innen getrackt: Welche Art von Filmen oder Serien hat er oder sie angesehen und wie beurteilt? Jetzt vergleicht der Algorithmus alle Nutzer:innen miteinander und geht davon aus, dass Menschen mit ähnlichen Nutzungsverhalten möglicherweise denselben Geschmack haben. So schlägt er dann Nutzer:innen Empfehlungen vor, die jemand anders mit gleichem Geschmack gut fand. Dafür werden riesige Datenmengen gebraucht – je mehr, desto besser, denn je weniger Trainingsdaten zur Verfügung stehen, desto schlechter sind die Ergebnisse der Software.
Mehr Wissenshunger?
Wenn Sie noch mehr über Künstliche Intelligenz lernen und etwas Recherche betrieben wollen, können wir den kostenlosen offenen KI online Kurs empfehlen, der von der Universität Helsinki entwickelt wurde. Die KI-Forscher haben es sich zum Ziel gemacht, mindestens 1% der Weltbevölkerung über Künstliche Intelligenz aufzuklären.


Ihre Meinung ist uns wichtig - wir freuen uns auf Ihren Kommentar