
/ 5 Minuten Lesezeit
Das menschliche Gehirn zum Vorbild: Deep Learning
Künstliche Intelligenz (KI) ist in aller Munde und viele haben mittlerweile eine grobe Vorstellung davon. Deep Learning ist jedoch noch weniger populär. Lernen ist für uns stark mit hoher menschlicher Intelligenz oder Bewusstsein konnotiert. In der Natur ist das Gehirn der Schlüssel zu Intelligenz: Das Bewusstsein ist als Teil der Intelligenz im Gehirn angesiedelt und das Verhältnis von Gehirnmasse zu Körpermasse gilt als Maßstab für Intelligenz bei Tieren. Nachdem die Evolution bekanntermaßen die besten Ideen hat und menschlichen Erfindungen immer wieder als Vorbild gedient hat, ist der nächste Schritt logisch: Der Versuch das Gehirn künstlich nachzubilden. Diese Bemühungen resultieren in state-of-the-art Algorithmen, die die Natur zum Vorbild haben, sogenannte Deep Learning Algorithmen. Damit können nun neue Herausforderungen angegangen werden, die ohne lernende Algorithmen nicht denkbar gewesen wären. Das können auch Aufgaben sein, die von uns Menschen tagtäglich ganz intuitiv erledigt werden. Zum Beispiel ist es für die meisten ein einfacher Prozess Gesichter zu erkennen – dabei ist es für uns egal, ob die Hälfte des Gesichts im Schatten liegt oder jemand etwa einen andersgefärbten Lippenstift trägt. Was für Menschen intuitiv ist, kann fast unmöglich für einen Computer sein: Wie soll ein Computer wissen, dass dies dasselbe Gesicht ist, wenn es anders aussieht als in den Daten, mit denen er es kennengelernt hat? Richtig, das kann er nicht. Naja, er konnte es nicht – das Konzept von Deep Learning war wahrlich ein Durchbruch auf diesem Gebiet.
Was ist Deep Learning?
Deep Learning ist ein Teilgebiet von Machine Learning, das wiederum selbst ein Teil von Künstlicher Intelligenz (KI) ist.
Das Gebiet der Künstlichen Intelligenz enthält Maschinelles Lernen und Deep Learning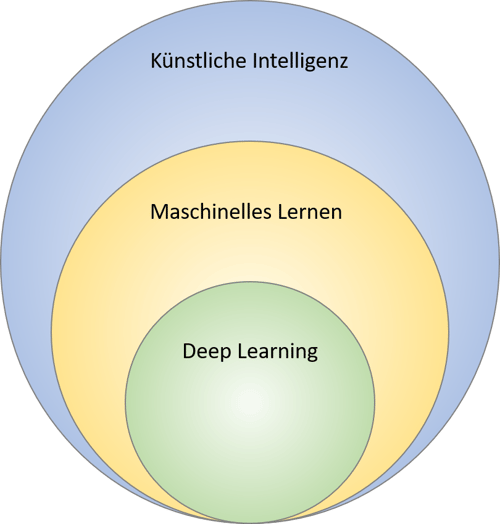
Grundsätzlich gibt es keine allgemeingültige Definition von KI und manchmal ist es schwer zu entscheiden, ob etwas unter den Begriff KI fällt. „Intelligenz“ ist ein Begriff, der nicht so selbsterklärend ist. Ein bekanntes Beispiel, um zu zeigen, wie vage der Begriff Intelligenz ist, ist der Turing Test. Dessen These ist: Etwas kann auf Grund seines Benehmens als intelligent bezeichnet werden. Der Grundgedanke des Tests geht folglich davon aus, dass ein Computer als intelligent gilt, wenn man nicht unterscheiden kann, ob der Kommunikationspartner Mensch oder Computer ist. Ein Chat-Bot beispielsweise gilt als intelligent, wenn man nicht sicher unterscheiden kann, ob er Mensch oder Bot ist. Natürlich hat der Bot kein Bewusstsein zum Thema und hat keine eigene Meinung – das zeigt die Schwierigkeit des Begriffs Intelligenz. Jeder Output, jede Antwort, die der Computer liefert, ist nur durch kluge Programmierung und viele Trainingsdaten möglich. Sogar die beste Deep Learning Software der Welt ist ohne Daten, von denen sie lernen kann, nichts wert.
Das Besondere an Deep Learning ist die Natur zum Vorbild zu haben. In einem Satz formuliert: Deep Learning Methoden ermöglichen es Maschinen menschliches Verhalten zu imitieren und sind deshalb dazu in der Lage sind zentrale Infos selbstständig zu identifizieren. Die meisten Methoden versuchen den Prozess der Informationsverarbeitung im menschlichen Gehirn durch Neuronen nachzubilden. Ein Neuron allein kann auch im künstlich nachgebildeten Netzwerk kein intelligentes Verhalten leisten, aber es kann Daten weiterverarbeiten und kurzfristig speichern. In Computern haben das vorher zwei komplett unterschiedliche Teile übernommen: Arbeitsspeicher und Festplatte.
Künstliche Neuronen
Für ein künstliches Neuron werden dieselben Begrifflichkeiten verwendet wie für sein natürliches Vorbild. Es besteht aus Dendriten, einem Zellkörper, einem Axon und Synapsen. Die Dendriten übermitteln Informationen zum Zellkörper und dem Axon und die Synapsen übertragen es dann wiederum ans nächste Neuron und so weiter. Ein künstliches Neuron allein kann sich nicht intelligent verhalten – genau wie im menschlichen Gehirn. Die einzelnen Neuronen sind zu Lagen verbunden, die wiederum miteinander in Verbindung stehen. Das Ergebnis ist ein komplexes Netz: ein tiefes oder mehrschichtiges neuronales Netzwerk. Selbstverständlich ist ein künstliches neuronales Netzwerk nicht ansatzweise so komplex wie das eines menschlichen Gehirns, die Natur ist also nicht mehr als ein Vorbild.
Jede Lage eines neuronalen Netzwerks hat einen bestimmten Zweck. Das bedeutet, dass sie bestimmte für diese Lage relevante Informationen aus dem gesamten Input erkennt und analysiert. Eine führende Disziplin im Deep Learning ist die Bildverarbeitung. Auch dabei haben die Lagen des neuronalen Netzwerks bestimmte Ziele: Eine Lage erkennt, ob die einzelnen Pixel im Bild hell oder dunkel sind, eine andere erkennt simple Formen. Eine Lage ist darauf trainiert bestimmte Objekte zu erkennen und eine andere Lage erkennt bestimmte Besonderheiten dieses Objekts.
Jedes neuronale Netzwerk braucht eine Input- und eine Output-Lage, zusätzlich kann es aber beliebig viele sogenannte „versteckte“ Lagen dazwischen haben. Lagen können unterschiedliche Lernmethoden verfolgen. Die bottom-layers, also unteren Lagen oder auch versteckte Lagen, lernen meistens unbetreut. Das bedeutet, dass sie ihr “Wissen” selbstständig aus den Daten erweitern. Sogenannte top-layers, also obere Lagen, werden oft durch betreutes Lernen trainiert. Das bedeutet, dass Menschen Informationen bereitstellen müssen. Beim Beispiel der Bildbearbeitung, können die top-layers die Struktur des Bildes durch helle und dunkle Pixel erkennen, während die bottom-layers Muster oder sich wiederholende Erscheinungen erkennen. Allein diese Kombination eröffnete schon völlig neue Möglichkeiten im künstlichen Lernen. Der eigentliche Meilenstein war es jedoch einen rückpropagierenden Algorithmus hinzuzufügen. Die Lagen geben ihre Informationen hierbei nicht einfach durch das Netzwerk weiter, sondern tauschen Informationen untereinander aus, geben sie auch zurück und vermeiden so Fehler. Um das zu erreichen, wird zunächst ein bestimmter Input für das neuronale Netzwerk vorbreitet und eingespeist. Als nächstes wird das Ergebnis der output-Lage bewertet und danach zurück in das Netzwerk gegeben. Der Unterschied ist dabei, dass die Neuronen, die vorher fehlerhafte Ergebnisse hatten niedriger gewichtet werden. So kann sich der Algorithmus selbst korrigieren. Dadurch wird die Lernkurve zwar dramatisch verbessert, aber andererseits werden sehr große Datenmengen benötigt, um bestimmte Merkmale zu erkennen: Das neuronale Netzwerk muss vor der Verwendung gut und gründlich trainiert werden, um korrekt zu funktionieren. Kennt der Algorithmus eine Spezifikation nicht, ist er demnach auch nicht in der Lage sie zu identifizieren.
Das neuronale Netzwerk
Das Konzept von Deep Learning war wahrlich ein Durchbruch. Google zum Beispiel gab bekannt, dass die sich daraus ergebenden Verbesserungen ihrer Sprachverarbeitungssoftware etwa 10 Jahre länger gedauert hätten, wenn sie manuell programmiert worden wären. Das ist jedoch nicht die einzige Anwendung, der wir Deep Learning Modelle in unserem Alltag begegnen.
Netflix und Spotify beispielsweise wählen die persönlichen Vorschläge für ihre Nutzer basierend auf deren Gewohnheiten aus – mit Hilfe eines neuronalen Netzwerks. Eine weitere häufig genutzte Anwendung für Deep Learning ist die Spracherkennung. Laut einer Studie von Statista aus dem Jahr 2019 ist die automatische Übersetzung von Sprache in Text die sechst-meist-genutzte Anwendung von KI-basierten Smartphone Apps. Doch nicht nur moderne Dienstleistungen nutzen KI-gestützte Prozesse, auch Spam Filter verwenden heutzutage Deep Learning Mechanismen.
Gesichtserkennung als typische Aufgabe für Deep Learning
Bildverarbeitung ist eine weitverbreitete Anwendung von Deep Learning. Für die meisten von uns ist es ein tagtäglicher Prozess Gesichter zu erkennen – dabei ist es für uns egal, ob die Hälfte des Gesichts im Schatten liegt oder jemand etwa einen andersgefärbten Lippenstift trägt. Beispielsweise ist die Gesichtserkennung von iOS 10, FaceID, im Grunde eine typische Gesichtserkennungssoftware, wobei sie einige speziellere Fähigkeiten kombiniert: Infrarotlicht macht es für die Software einfacher das Gesicht vor dem Smartphone zu erkennen. Ein Projektor projiziert dann etwa 30.000 Punkte auf das Gesicht des Nutzers. Danach beginnt der Deep Learning Prozess der Farb- und Formerkennung, der durch das neuronale Netzwerk rollt. Die Aufnahme der Infrarot Kamera wird dann mit den Bildern verglichen, die auf dem Handy während des FaceID Setups gespeichert wurden. Um das Gesicht immer besser erkennen zu können, muss der Algorithmus permanent lernen und die Rückpropagierung beginnt. So funktioniert der Algorithmus immer noch, wenn der Nutzer seine Haarfarbe wechselt oder andere Accessoires trägt, solang genügend Merkmale erkennbar sind. FaceID funktioniert also je besser, desto mehr es genutzt wird und desto größer die so gelernte Datenmenge ist.
Lernen in der Zukunft
Ein Problem, dem Entwickler noch gegenüberstehen ist die limitierte Kapazität von Rechenkapazität und Speicher auf kleinen Geräten, wie Smartphones. Deep Learning benötigt riesige Datenmengen, um bestimmte Merkmale erkennen zu können. Das ist die Verbindung zwischen Big Data und Deep Learning. Wie schon erwähnt, ist der Fortschritt durch Deep Learning gewaltig. Daher ist es keine Option Deep Learning einfach nicht zu nutzen und die Geräte brauchen Zugriff zu einem Machine Learning Algorithmus. Kleine Geräte nutzen deshalb das Internet, um auf ein neuronales Netzwerk zuzugreifen und Daten auszutauschen. Das ist jedoch nicht für alle Probleme die Lösung. Insbesondere für selbstfahrende Fahrzeuge, ist die visuelle Verarbeitung ihrer Umwelt elementar. Ein Fahrzeug muss erkennen, ob Hindernisse Menschen, Dinge oder Schilder sind und diese entsprechend verarbeiten mit Hilfe von KI. Wäre die Verbindung zum Internet in solch einer Situation unterbrochen, könnte dies fatale Folgen haben.
Forscher und Entwickler suchen derzeit nach Lösungen, um die Anforderungen an Geräte für KI zu minimieren. Da der Fortschritt in den Bereichen künstliche Intelligenz, Machine Learning und Deep Learning solch große Schritte macht, wird es zweifelsohne bald eine Lösung geben. Tatsächlich wurde an der Northeast University in Boston eine vielversprechende Idee vom Forscher Yanzhi Wang entwickelt: Er erfand einen Algorithmus, der sich selbst entwickelt. Dadurch ist er klein genug, um auch auf kleinen Endgeräten zu funktionieren.
Machine Learning ist ein wachsender Teil unseres Alltags und wird Schritt für Schritt weiter verbessert werden. Science-Fiction Szenarien müssen trotzdem mit Vorsicht genossen werden, insbesondere wenn es um Computer mit Bewusstsein geht – oder träumende Computer. Googles „Dreamgenerator“ ist eine KI-Software, die vermuten lässt, dass es um träumende Maschinen geht, das hat jedoch nichts mit menschlichen Träumen gemeinsam. Aber wer weiß, was die Zukunft bringt...
Falls Sie noch immer etwas verwirrt von den Begriffen Künstliche Intelligenz, Machine Learning und Deep Learning sind, könnte Ihnen dieser Artikel weiterhelfen.



Ihre Meinung ist uns wichtig - wir freuen uns auf Ihren Kommentar